On peut détecter un overfitting en surveillant les performances du modèle sur les données d'entraînement et de test au fil du temps. Si les performances du modèle sur les données d'entraînement continuent de s'améliorer tandis que celles sur les données de test diminuent, cela indique un surapprentissage.
Qu'est-ce que l overfitting dans l'apprentissage automatique Machine Learning )? L'overfitting est l'un des pires ennemis du Data Scientist. Il s'agit d'un problème fréquemment rencontré en Machine Learning. Il survient lorsque le modèle essaie de trop s'adapter aux données d'entraînement. Il est trop flexible et trop complexe et s'adapte à des données qui ne sont pas forcément à prendre en compte.
Comment définir le sur apprentissage overfitting ?
L'Overfitting (sur-apprentissage) désigne le fait que le modèle prédictif produit par l'algorithme de Machine Learning s'adapte bien au Training Set. Comment Peut-on sortir du problème de surapprentissage ? Régularisation. Une autre méthode permettant d'éviter le surapprentissage est d'utiliser une forme de régularisation. Durant l'apprentissage, on pénalise les valeurs extrêmes des paramètres, car ces valeurs correspondent souvent à un surapprentissage.
Comment lutter contre l overfitting ?
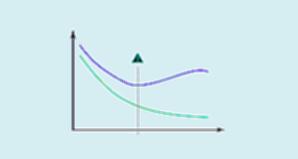
Pour éviter l'overfitting, il faut donc réévaluer le modèle à chaque fois sur des données non vues pendant l'entraînement. Une bonne pratique est de séparer son jeu de données initiales en un jeu d'entraînement (train set) et un jeu de test (test set). Le premier servira à entraîner le modèle. Quelle est la différence entre l'apprentissage non supervisé et l'apprentissage supervise ? Supervisé: toutes les données sont étiquetées et les algorithmes apprennent à prédire le résultat des données d'entrée. Non supervisé: toutes les données ne sont pas étiquetées et les algorithmes apprennent la structure inhérente à partir des données en entrée.
Pourquoi overfitting ?

L'overfitting intervient lorsque l'erreur sur les données de test devient croissante. Typiquement, si l'erreur sur les données d'entraînements est beaucoup plus faible que celle sur les données de test, c'est sans doute que votre modèle a trop appris les données. Quelles sont les causes du sous ajustement ? Le sous-ajustement se produit d'habitude lorsqu'il n'y a pas assez de données ou lorsqu'on essaie de construire un modèle linéaire avec des données non-linéaires. Conséquemment, le modèle est trop simple pour faire des prédictions correctes.
Pourquoi la validation croisée ?
La validation croisée permet de tirer plusieurs ensembles de validation d'une même base de données et ainsi d'obtenir une estimation plus robuste, avec biais et variance, de la performance de validation du modèle. Qu'est-ce que l'apprentissage automatique inductif ? L'apprentissage automatique est une branche de l'intelligence artificielle (IA) et de l'informatique qui utilise principalement des données et des algorithmes pour imiter la manière dont les être humains apprennent, en améliorant progressivement sa précision.